논리 구조(Logical Structure)와 물리 구조(Physical Structure)의 이해
안녕하세요, 모던이입니다. IT 분야에서 논리 구조와 물리 구조는 중요한 역할을 수행하지만, 그 목적과 사용 방식에서 차이가 있습니다. 이 글에서는 각 구조의 정의와 특징, 그리고 주요 차이점에 대해 알아보겠습니다.
논리 구조(Logical Structure)
- 추상성: 논리 구조는 데이터의 추상적인 표현을 제공하며, 업무 개념과 관계에 중점을 둡니다. 데이터 엔티티와 관계를 시각화하는 데에 엔티티 관계 다이어그램(ERD)이 사용됩니다.
- DBMS 독립성: 이 모델은 특정 데이터베이스 관리 시스템(DBMS)에 의존하지 않으며, 기술적인 세부 사항보다는 비즈니스 로직을 설명하는 데 초점을 맞춥니다.
- 정규화: 데이터 중복을 최소화하고 데이터 무결성을 향상시키는 데 중점을 두며, 데이터를 정규화하는 방법을 채택합니다.
- 사용자 중심: 주로 데이터 아키텍트와 비즈니스 분석가에 의해 생성되며, 비즈니스 사용자가 데이터 요구 사항을 이해하는 데 도움을 줍니다.
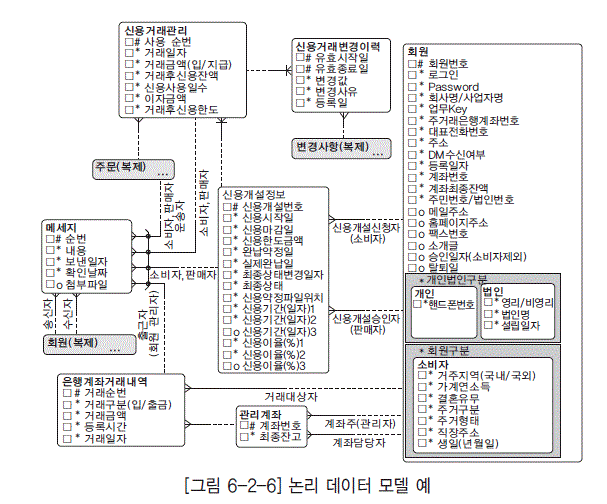
물리 구조(Physical Structure)
- 구체성: 물리 구조는 데이터베이스의 구체적인 구조를 제공하며, 특정 DBMS와 저장 기술과 밀접하게 통합됩니다.
- DBMS 통합: 이 모델은 특정 DBMS와 관련된 기술적 세부 사항을 정의하며, 예를 들어 테이블, 컬럼, 제약 조건 등을 포함합니다.
- 비정규화: 성능 최적화를 위해 때때로 비정규화를 포함할 수 있으며, 이는 데이터 검색 속도를 높이기 위해 데이터 중복을 허용합니다.
- 개발자 중심: 주로 데이터베이스 관리자와 개발자에 의해 구현되며, 실제 데이터베이스 구현을 안내합니다.
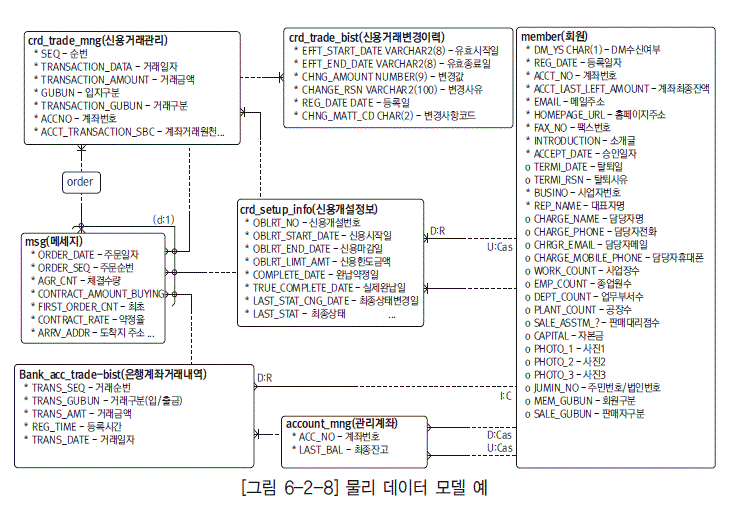
논리 구조와 물리 구조 사이의 전환 과정
논리 구조와 물리 구조 사이의 전환은 IT 분야에서 중요한 프로세스입니다. 이 과정은 데이터 모델링과 시스템 설계에서 핵심적인 역할을 합니다. 아래에서는 이 전환 과정에 대해 자세히 설명합니다.
논리 구조에서 물리 구조로의 전환
- 논리 구조의 설계는 비즈니스 요구 사항과 데이터 관계를 정의하는 과정으로 시작합니다. 이 단계에서는 엔티티 관계 다이어그램(ERD)을 사용하여 데이터 엔티티와 그들 사이의 관계를 시각화합니다.
- 물리 구조로의 전환은 논리 모델이 정의한 엔티티와 관계를 실제 데이터베이스 구조로 변환하는 과정입니다. 이 과정에서는 특정 DBMS의 기술적 요구 사항과 제한 사항을 고려하여 설계됩니다.
전환 과정은 기술적 세부 사항을 정의하는 것을 넘어, 시스템의 성능, 보안, 확장성 및 유지 관리를 보장하는 목표를 가지고 있습니다.
Q1. 논리 구조와 물리 구조의 차이점은 무엇인가요?
논리 구조는 데이터의 추상적인 표현을 제공하며, 업무 개념과 관계에 중점을 둡니다. 이는 데이터 엔티티와 관계를 엔티티 관계 다이어그램(ERD)을 사용하여 시각화하는 것을 포함합니다. 반면, 물리 구조는 데이터베이스의 구체적인 구조를 제공하며, 특정 DBMS와 저장 기술과 밀접하게 통합됩니다.
Q2. 데이터 모델링의 3단계는 무엇이며, 각 단계에서 수행하는 주요 작업은 무엇인가요?
데이터 모델링의 세 단계는 개념적 데이터 모델링, 논리적 데이터 모델링, 물리적 데이터 모델링입니다. 개념적 데이터 모델링에서는 엔티티와 그 관계를 찾아내고 E-R Diagram을 생성합니다. 논리적 데이터 모델링에서는 엔티티 중심의 데이터 모델을 구체화하고, 트랜잭션 인터페이스를 설계하며 정규화와 참조 무결성 규칙을 정의합니다. 마지막으로, 물리적 데이터 모델링에서는 논리 데이터 모델을 데이터 저장소로서 어떻게 구현할 것인가에 대해 다룹니다.
Q3. 물리적 데이터 모델링이 중요한 이유는 무엇인가요?
물리적 데이터 모델링은 데이터의 저장 공간, 데이터의 분산, 데이터 저장 방법을 고려하는 단계이며, 이 과정에서 결정되는 많은 부분이 데이터베이스의 운용 성능으로 나타나므로 중요합니다.
Q4. 데이터베이스에서 세그먼트와 익스텐트의 역할은 무엇인가요?
세그먼트는 데이터베이스 내에 생성되는 모든 객체(테이블, 인덱스 등)들을 의미하며, 하나의 세그먼트는 하나의 테이블스페이스에 저장되는 하나의 구성요소입니다. 익스텐트는 하나의 세그먼트가 여러 개의 익스텐트가 모여서 구성되며, 하나의 테이블을 생성할 때, 처음에는 익스텐트라는 공간이 할당되고, 이 공간이 모두 사용되면 다시 익스텐트를 할당 받아 연속적으로 데이터를 저장하게 됩니다.
Q5. 데이터베이스 설계에서 테이블 통합의 장점은 무엇이며, 어떤 경우에 테이블 분할을 고려해야 하나요?
테이블을 통합하는 주요 장점은 I/O 처리 효율의 증가와 응답 시간의 단축입니다. 데이터베이스가 둘 이상의 테이블을 조인하는 것보다 하나의 테이블을 참조하는 쪽이 훨씬 빠르기 때문입니다. 반면, 테이블 분할은 한 개체에 포함된 속성의 수가 많아지거나 텍스트 입력을 위해 길이를 크게 설정할 경우 레코드의 크기를 넘어서는 경우 고려해야 합니다. 이 경우 분할에 의해 테이블의 조인이 발생하게 되지만, 확장 영역으로 분할된 레코드를 검색하는 것보다는 훨씬 부하가 줄어듭니다.